Índices rowstore x columnstore
 Tempo de leitura: 7 minutos
Tempo de leitura: 7 minutos
Fala pessoal, tudo bom? vamos ao primeiro post no blog novo..
Hoje venho falar um pouco sobre índices rowstore x columnstore, introduzindo um conceito teórico e um laboratório.
Índices são criados com objetivo de trazer performance para as consultas e existem diversas formas de serem criados de acordo com uma análise elaborada dentro do negócio, mas isso é um assunto para outro post.
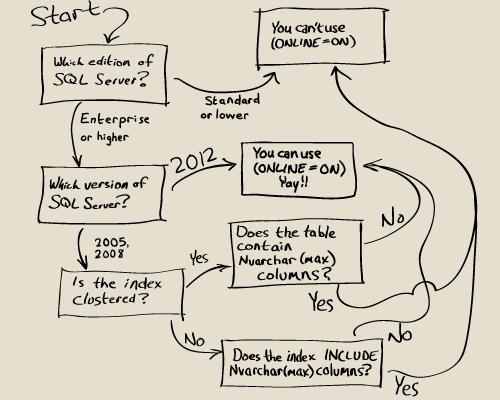
Os índices columnstore foram introduzidos no SQL Server 2012 e a cada lançamento de versão do SQL Server, são aprimorados. Entretanto, a impressão que tenho como DBA é que a utilização desse recurso, ainda é pouca de uma forma geral, comentem se estou equivocado.
Você pode verificar se a sua versão está apta para implementação dos índices columnstore no link: Recursos das versões SQL Server
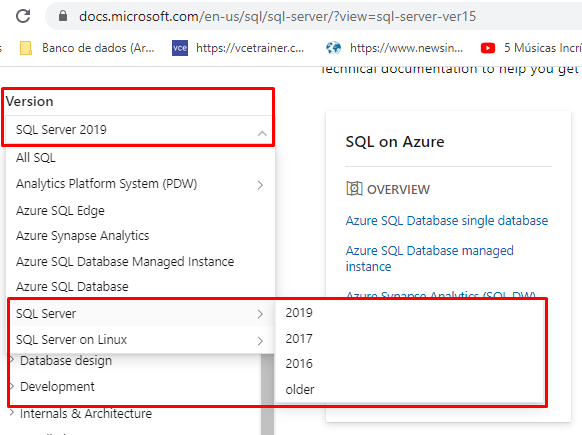
Versões do SQL Server
Mas o que há de tão especial nos índices columnstore? Segundo as documentações da Microsoft, esses índices podem trazer ganhos significativos para consultas em ambientes de BI e data Warehousing, comparado aos índices tradicionais rowstore.
Diferença entre os índices rowstore vs ColumnStore
- Rowstore: Indexação tradicional que existe desde o inicio do SQL Server, são projetados para otimizar a recuperação de dados permitindo que consultas se submetam a uma rápida localização através do índice ao invés de varrer toda a tabela. É importante enfatizar que o SQL Server cria esse tipo de índice organizando as linhas e colunas, armazenando fisicamente as páginas de dados a nível de linhas.
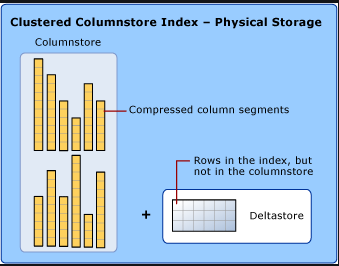
- ColumnStore: Essa arquitetura de índice também é logicamente organizada a nível de linha e coluna. Mas então qual é a diferença? Fisicamente os dados são organizados em uma segmentação de dados em colunas e não em linhas.
Segue uma exemplificação melhor na imagem abaixo:
columnstore x rowstore
Principais Ganhos ao usar o columnstore
A primeira coisa que preciso deixar claro é que os índices columnstores não são nem um pouco indicados para buscas individuais. Caso seja esse o seu objetivo, use um índice rowstore tradicional e com cautela. Esse tipo de índice funciona muito melhor para ambientes OLAP (Online Analytical Processing), ou seja, processamento de uma alta carga de dados, ETL. O mesmo tende a ser melhor para execução de leituras e consequentemente gravações sequenciais.
Um outro ganho que não posso deixar de mencionar é que o SQL Server a partir da versão 2016 disponibiliza que o columnstore seja criado afim de combinar transações OLTP (Online Transacion Processing) e fornecer a visualização de análises em tempo real, isso quer dizer que você pode oferecer suporte de consultas de BI por exemplo e ao mesmo tempo fornecer consultas OLTP , isso tudo em tempo real. É lógico que tudo tem um preço, você vai consumir mais espaço em disco, memória, porém é possível.
Laboratório
Irei demonstrar rapidamente um laboratório e evidenciar o uso dos dois tipos de índices mencionado no artigo.
Para iniciar o laboratório, precisamos baixar um backup disponibilizado pela própria microsoft e restaurar no ambiente de teste.
Baixe no link, o arquivo AdventureWorksDW2016. bak e restaure o backup no seu ambiente de teste.
Para este laboratório, iremos utilizar uma tabela que já vem populada e com seu devido índice. Para realizar o laboratório de uma forma mais detalhada, vamos excluir o índice existente.
1) Execute o comando abaixo:
USE [AdventureWorksDW2016_EXT] GO ALTER TABLE [dbo].[FactResellerSalesXL_PageCompressed]DROP CONSTRAINT [PK_FactResellerSalesXL_PageCompressed_SalesOrderNumber_SalesOrderLineNumber] GO
Esse comando irá apagar o índice da tabela [FactResellerSalesXL_PageCompressed] que foi criado automaticamente com a PRIMARY KEY .

A título de informação, a tabela utilizada denominada FactResellerSalesXL_PageCompressed possui 11669638 de registros.
Vamos verificar os primeiros resultados com a tabela sem nenhum tipo de índice.
2) Execute a seguinte consulta:
USE [AdventureworksDW2016_EXT] GO DBCC DROPCLEANBUFFERS SET STATISTICS IO ON SET STATISTICS TIME ON SELECT s.SalesTerritoryRegion,d.[CalendarYear],FirstName + ' ' + lastName as 'Employee',FORMAT(SUM(f.SalesAmount),'C') AS 'Total Sales', SUM(f.OrderQuantity) as 'Order Quantity', COUNT(distinct f.SalesOrdernumber) as 'Number of Orders', count(distinct f.Resellerkey) as 'Num of Resellers' FROM FactResellerSalesXL_PageCompressed f INNER JOIN [dbo].[DimDate] d ON f.OrderDateKey= d.Datekey INNER JOIN [dbo].[DimSalesTerritory] s on s.SalesTerritoryKey=f.SalesTerritoryKey INNER JOIN [dbo].[DimEmployee] e on e.EmployeeKey=f.EmployeeKey WHERE FullDateAlternateKey between '1/1/2005' and '1/1/2007' GROUP BY d.[CalendarYear],s.SalesTerritoryRegion,FirstName + ' ' + lastName ORDER BY SalesTerritoryRegion,CalendarYear,[Total Sales] desc SET STATISTICS IO OFF SET STATISTICS TIME OFF
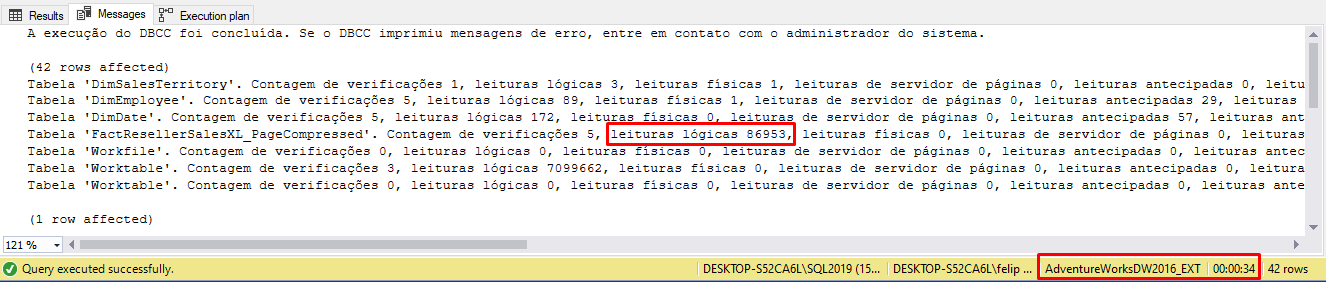
O tempo da execução dessa consulta no meu computador foi de 00:34 segundos, com um total de leituras lógicas de 86.953, conforme imagem:
Nessa segunda etapa, vamos recriar o índice que havíamos apagado, o mesmo é do tipo tradicional conhecido como rowstore.
3) Crie o índice com o comando abaixo:
Obs: Tipo e estrutura de índice definido pelo próprio backup da Microsoft.
USE [AdventureWorksDW2016_EXT] GO CREATE CLUSTERED INDEX [PK_FactResellerSalesXL_PageCompressed_SalesOrderNumber_SalesOrderLineNumber] ON [FactResellerSalesXL_PageCompressed] ( [SalesOrderNumber] ASC, [SalesOrderLineNumber] ASC ) GO
Depois de ter criado o índice rowstore acima, execute a mesma consulta da etapa 2:
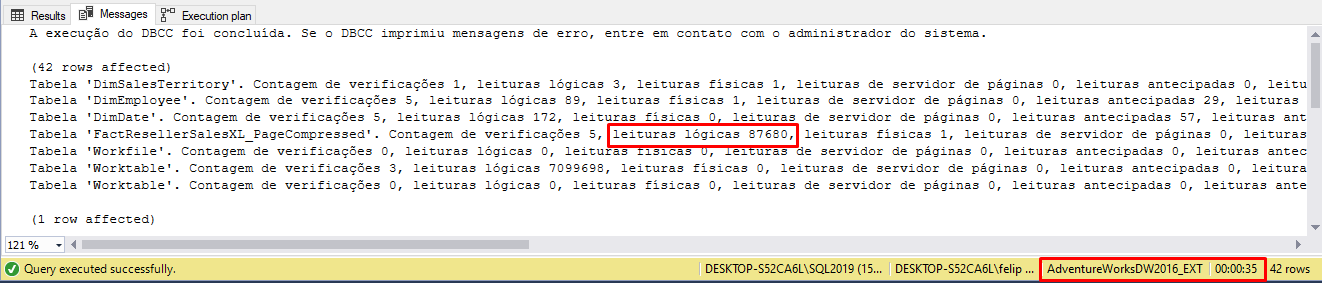
Perceba que o índice que vem criado nesse backup, para esse cenário, eu não diria que piorou, mas os tempos de execuções com e sem o índice rowstore ficaram bem próximos. Com índice, a quantidade de leituras lógicas aumentou um pouco inclusive, realizando um total de 87.680 leituras.
4) Vamos repetir o processo da etapa 1, e excluir o índice existente e em sequência criar o índice columnstore.
5) Nessa etapa, vamos criar um índice do tipo columnstore e rever os resultados. Execute o comando abaixo:
USE [AdventureWorksDW2016_EXT] GO CREATE CLUSTERED COLUMNSTORE INDEX [IndiceColumnstoreLAB] ON [dbo].[FactResellerSalesXL_PageCompressed] GO
6) Após criar o índice, e executar a mesma consulta trabalhada até o momento. A consulta da etapa 2, veja os resultados:
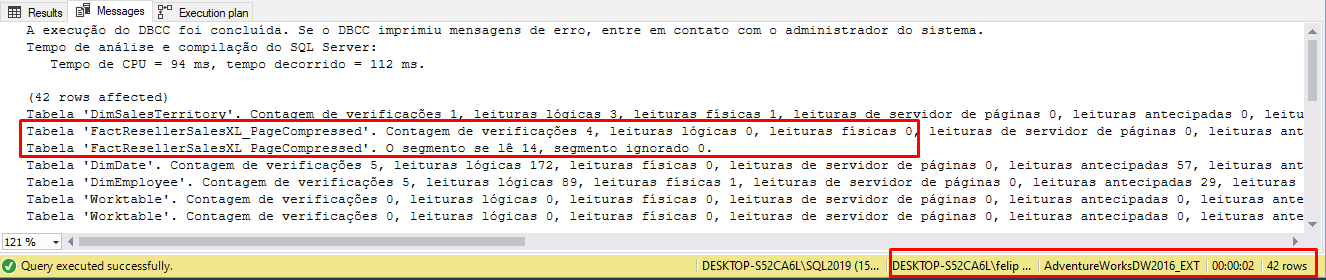
Veja que o tempo de execução reduziram de uma média de 30 segundos para 02 segundos, as leituras lógicas também foram mínimas.
Veja a utilização do índice no plano de execução:

Referências:
- https://www.brentozar.com/archive/2017/09/key-lookups-columnstore-indexes/
- https://blog.sqlauthority.com/2019/11/25/sql-server-columnstore-index-displaying-actual-number-of-rows-to-zero/
Conclusão
Vale a pena implementar? Como diz a galera por ai, não sei… Tudo vai depender do seu cenário, mas é claro que o ganho de performance é evidente.
Futuramente pretendo implementar essa solução em ambientes reais para testar e posto novamente os resultados da implementação em um ambiente real.
Qualquer dúvida, deixa seu comentário.

