AWS: Serviço CLOUDENDURE para ambientes disaster e recovery – migrações
 Tempo de leitura: 6 minutos
Tempo de leitura: 6 minutos
Fala pessoal, quanto tempo não é mesmo?
Em outros locais, existem arquiteturas mais elaboradas, como por exemplo, ambientes que funcionam em stand-in, log shipping, soluções de alta disponibilidade e por ai vai…. É um assunto bastante complexo, e pensando nisso, vou apresentar o serviço do cloudendure.
Atualmente diversos serviços oferecidos pela AWS, Azure, Google Cloud, Oracle, etc. Recentemente voltei a ter contato de forma mais profunda com o CloudEndure. Meus amigos? Que serviço espetacular.
Sem mais delongas, vamos entender a visão geral do serviço:
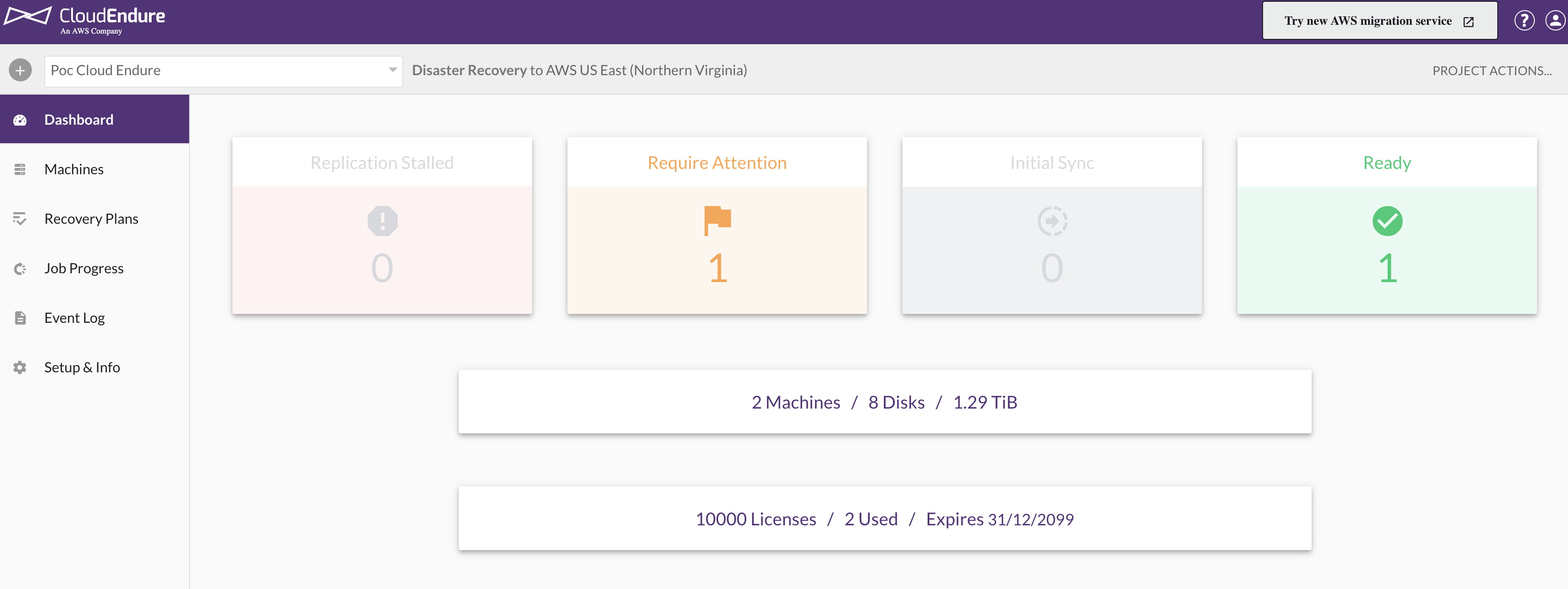
Console CloudEndure
Como funciona?
CloudEndure é uma empresa interna da própria AWS e pode ser usado para migrações de ambientes on-premisses para CLOUD ou como plano de desastre e recuperação.
Serviços: Disaster Recovery e Migration
O serviço oferece a clonagem de uma máquina a nível de bit, ou seja, os discos, arquivos e configurações são todos migrados/clonados.
O serviço de replicação é feito através de um agent que o próprio cloudendure fornece. O agent é instalado no servidor origem e realiza a cópia do servidor para um destino selecionado.
O serviço oferece instruções e após a instalação do agent no servidor origem, ele será exibido na aba machines da console.
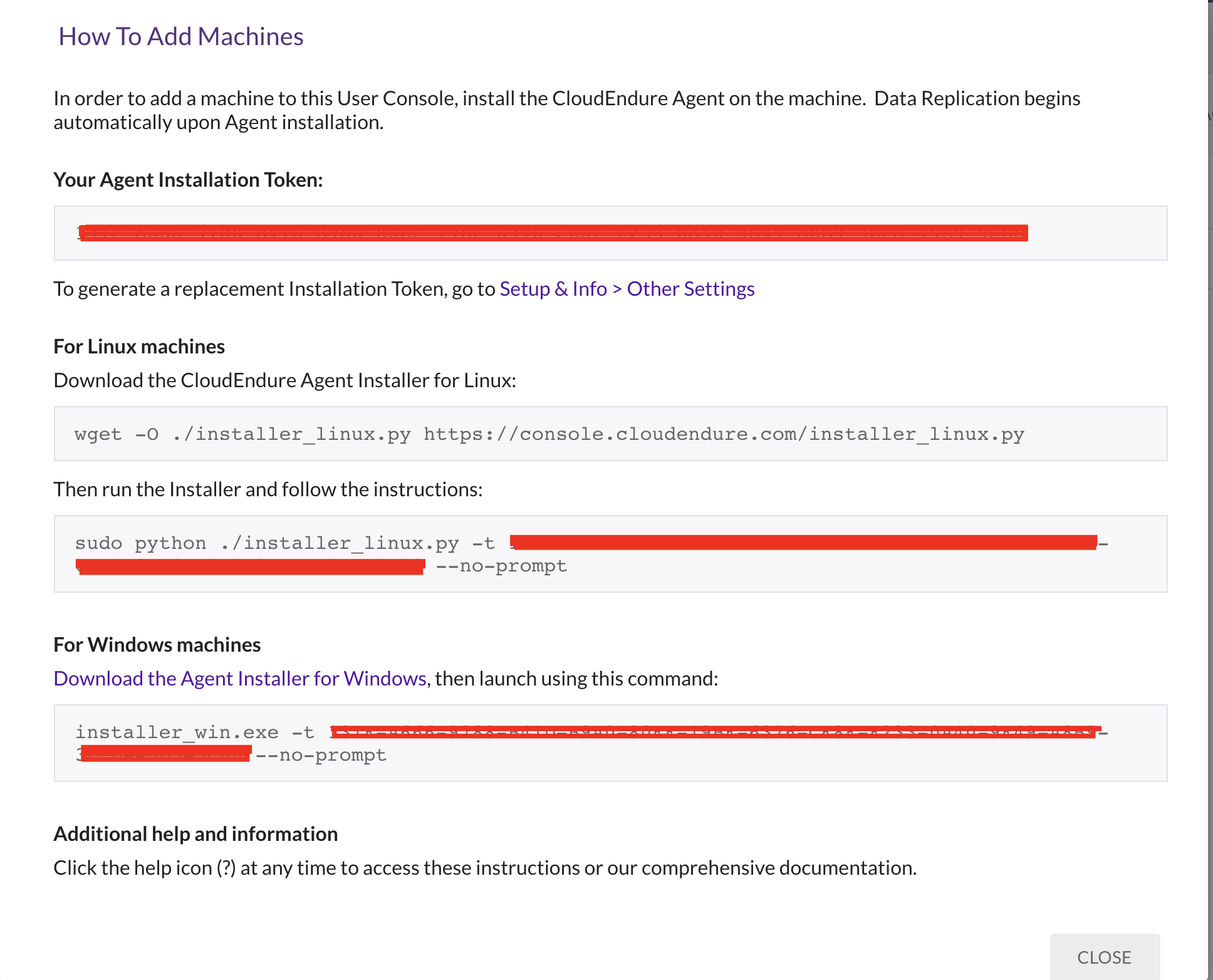
Configuração do Agent para origem
Demonstração:
- Você pode criar uma conta na console pelo link: https://console.cloudendure.com/
- Dentro da console é possível configurar vários parâmetros na aba replication settings, como por exemplo origem e destino.

3. Trazendo para um cenário AWS, é possível deixar certos parâmetros já configurados como por exemplo: VPC, Security Group, etc.
Perceba na imagem abaixo que é possível selecionar o tipo de instancias que irá realizar a replicação e também a conversão em um possível recovery/failback. O CloudEndure usa máquinas de apoio para que tudo seja realizado sem impacto nos ambientes de origem ou produção. Sendo assim, dependendo do tipo de instancia definida, o recovery/failback pode ser um processo mais rápido ou demorado.

No cenário acima, foram criadas duas instancias da família T.micro dentro da AWS:

Seleção de origem e destino CloudEndure
4. Com os servidores origem já sincronizados através dos agents, é possível montar “blueprints“, por exemplo: Na AWS, como será a máquina de recovery? Pode ser um servidor melhorado ou até mesmo um servidor mais tranquilo. Pode ser um servidor como um novo IP, com um novo security group, VPC e etc. É importante entender que o cloudendure cria máquinas para replicações e máquinas para recovery de fato.
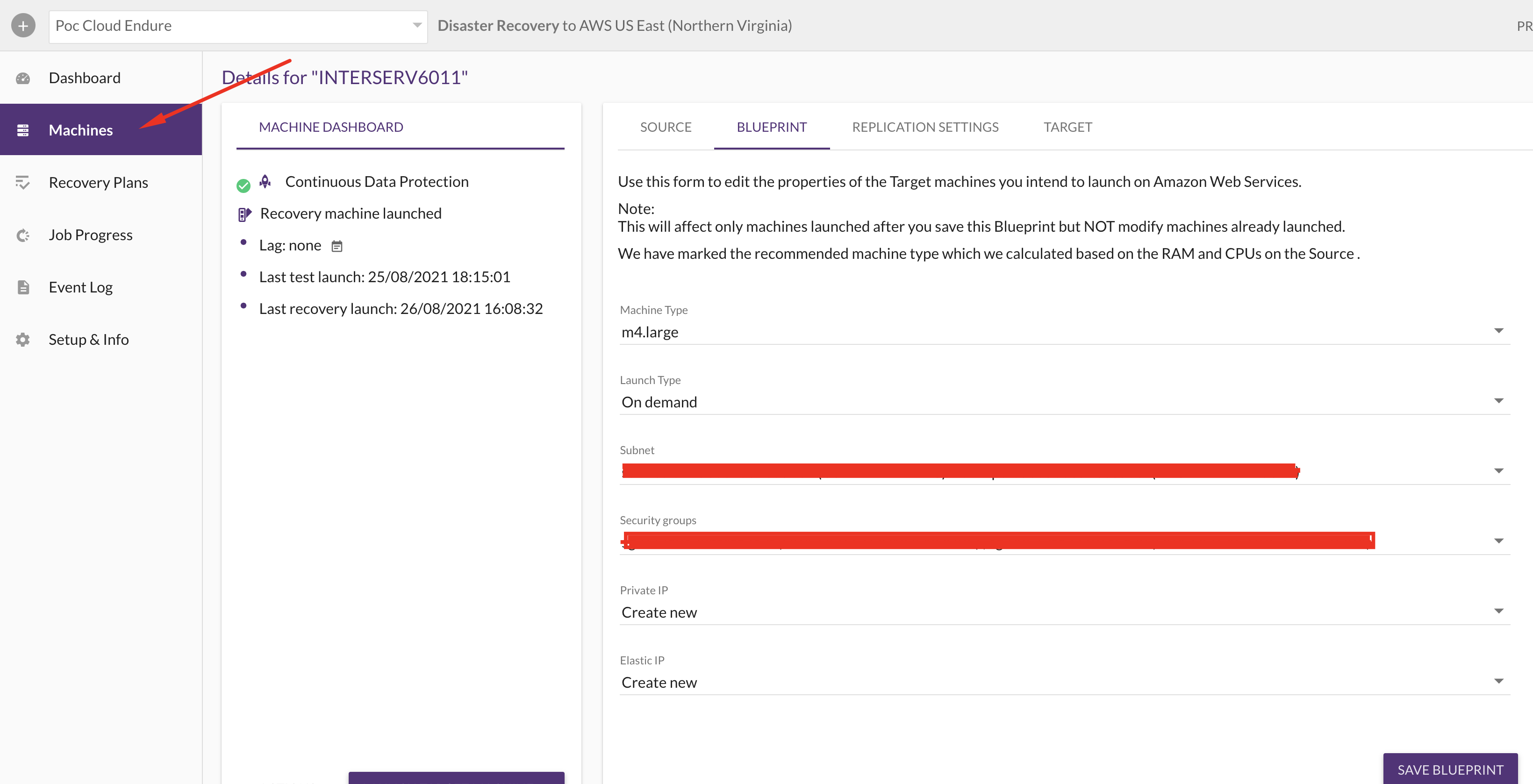
Inserção de blueprint/configuração
5. Antes de qualquer procedimento, o cloudendure necessita sincronizar e replicar todas as machines configuradas.
Após toda sincronização e configuração como funciona o recovery? De modo bem simples, você seleciona a opção recovery e seleciona um point-time
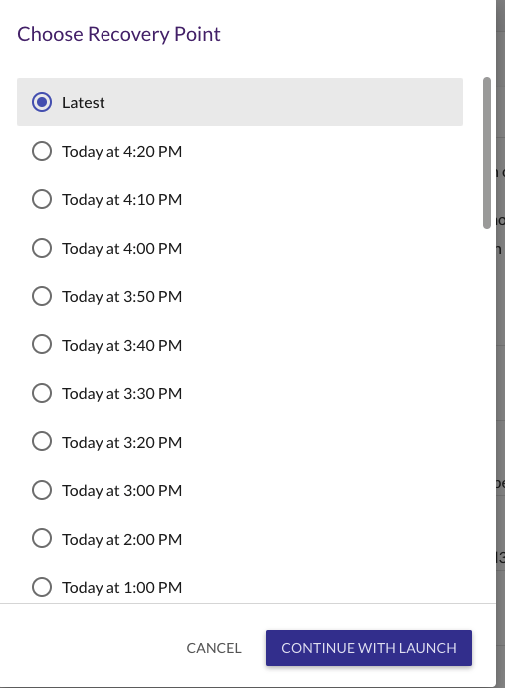
Checkpoint-time para recovery
6. Após isso, um job será iniciado e sua máquina começará a ser criada no destino selecionado, tudo gerenciado pelo próprio cloudendure.
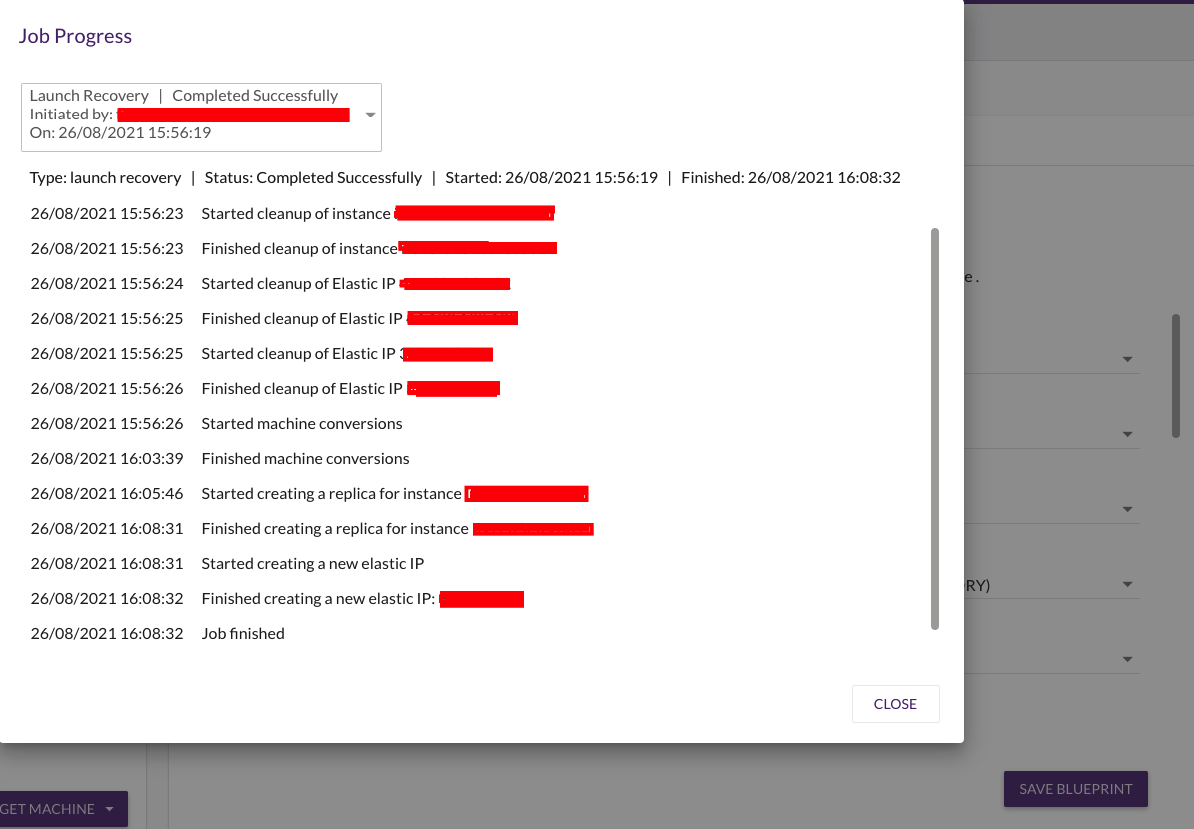
JOB de recuperação para possíveis recovery/failback
7. Após a finalização do JOB, sua máquina está disponível para uso correspondendo com o point-time definido e com as mesmas definições de origem. Simples e prático!
8. A nível de SQL Server, temos os seguintes resultados:
Fiz 3 inserts na maquina origem em uma tabela temporária, em determinados intervalos de tempo.
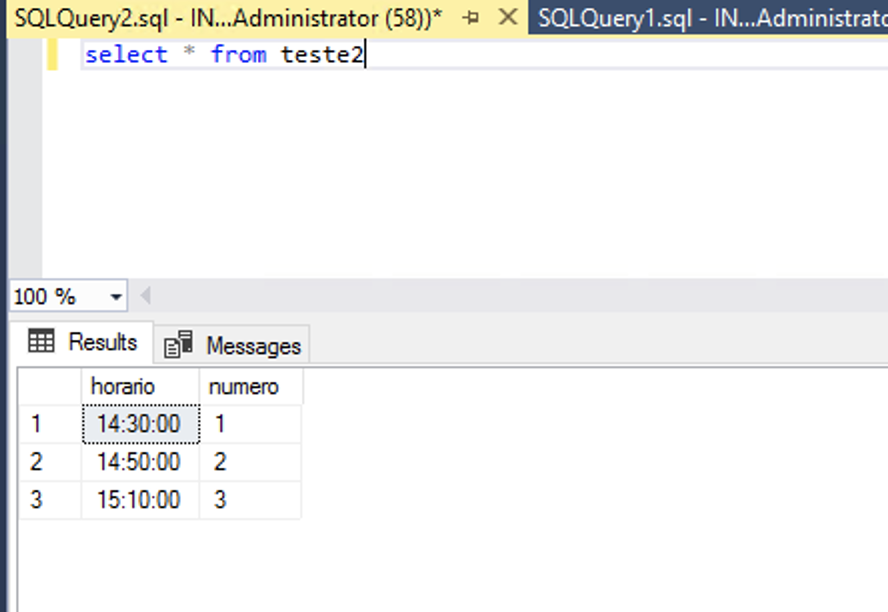
Inserts no SQL Server máquina de origem
Selecionei um recovery no check-point de 14:40m e o resultado na instancia criada foi:
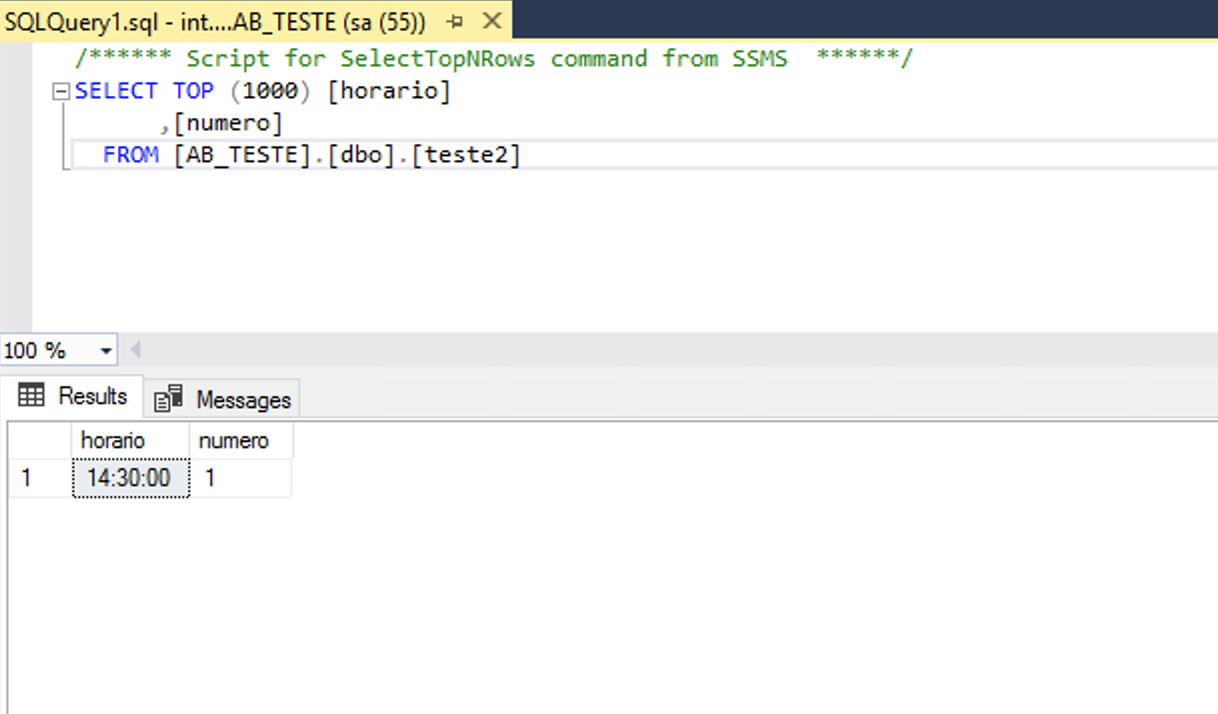
SQL Server no checkpoint 14:40 após recovery
Conclusão
Particularmente, achei a ferramenta bastante acessível e simples de entender. Foge de um esforço tradicional imenso, trás produtividade, agilidade e me arrisco a dizer que até mais economia a longo prazo!
O Cloudendure também disponibiliza um curso de usabilidade gratuito na sua página oficial e também uma boa documentação.
Treinamentos:
- https://www.aws.training/Details/eLearning?id=50309
- https://www.aws.training/Details/eLearning?id=71732
Documentação oficial:
E ai, gostou? Espero que sim. Qualquer dúvida comenta, que respondemos em breve.

