[Dicas rápidas] SQL Server: Restore em 100% demorando para concluir
 Tempo de leitura: 3 minutos
Tempo de leitura: 3 minutos
Fala, pessoALL! Tudo certo com vocês?
Nem vou usar aquela velha promessa de “vou tentar aparecer mais por aqui”… rs 😅
Passando rapidinho pra compartilhar uma dica envolvendo restore no SQL Server.
Essa semana precisei restaurar um banco de apenas 250GB no SQL Server 2022 — banco pequeno, né? 😄
Tudo corria bem, até que o processo travou em 100% e… nada de concluir.
Esperei 10, 20, 25 minutos naquela tela de 100% e aí acendeu o alerta: tem algo errado aqui.
Fui verificar os recursos do servidor: disco, CPU, memória… tudo subutilizado. Ou seja, claramente não era gargalo de infraestrutura.
Investigação:
E aí vem a pergunta: por onde começar a investigar?
Com certeza comecei desconfiando do IFI (Instant File Initialization) , conferi se estava habilitado, verifiquei que sim, então desativei e ativei novamente o IFI só para garantir. Após realizar essa ação estagnei no mesmo ponto.
Pesquisando um pouco, verifiquei o IFI é mais voltado para arquivos .MDF e .NDF mas que não se aplica muito bem aos arquivos de logs (.Ldfs).
Opa, ao ler isso já fui imaginando que poderia ser algo relacionado ao arquivo de Log da base, então ativei as seguintes Trace Flags:
- TF 3004: Essa traceFlag permite visualizar quando operações de zeragem acontecem, tanto em arquivos de disco quanto em arquivos de log.
- TF 3605: Essa traceFlag exibe o resultado de operações do DBCC no arquivo de error log.
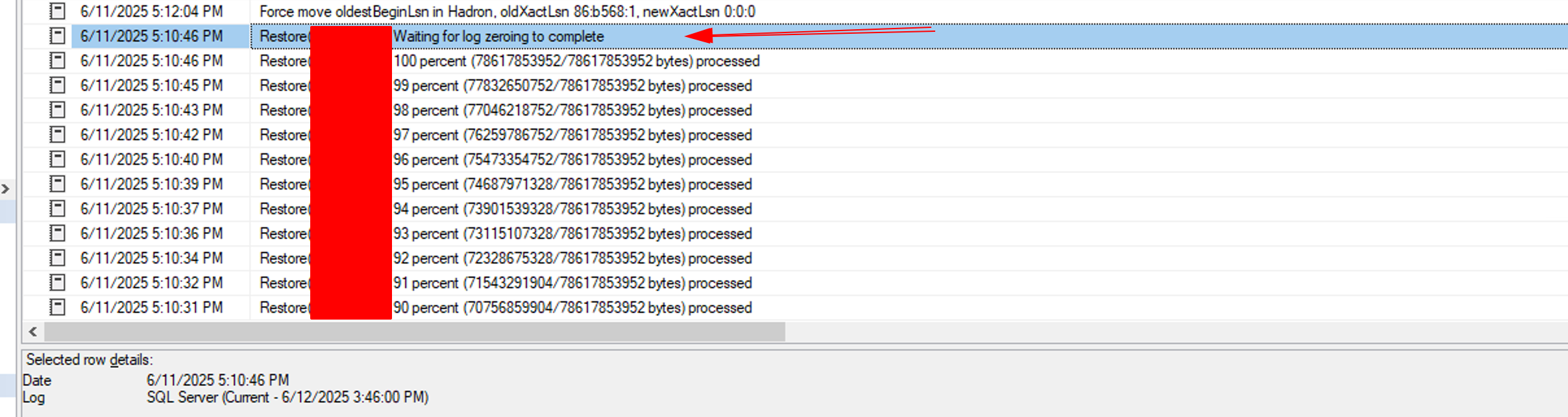
Habilitando as traces flags acima, cheguei ao seguinte resultado:
Operação que mostra o zeroing ocorrendo no arquivo de log
Pronto! Já tinha em mãos a evidência e a causa raiz do motivo pelo qual o restore estava levando uma eternidade para concluir. Agora, só faltava resolver o problema.
E qual foi a solução?
Por mais curioso que pareça, dias antes havia ocorrido um estouro de disco relacionado ao arquivo de log de algumas bases, causado por operações da aplicação que escreviam de forma desordenada no log.
Ligando os pontos, decidi agir: fiz um shrink no arquivo de log e, em seguida, gerei um novo backup.
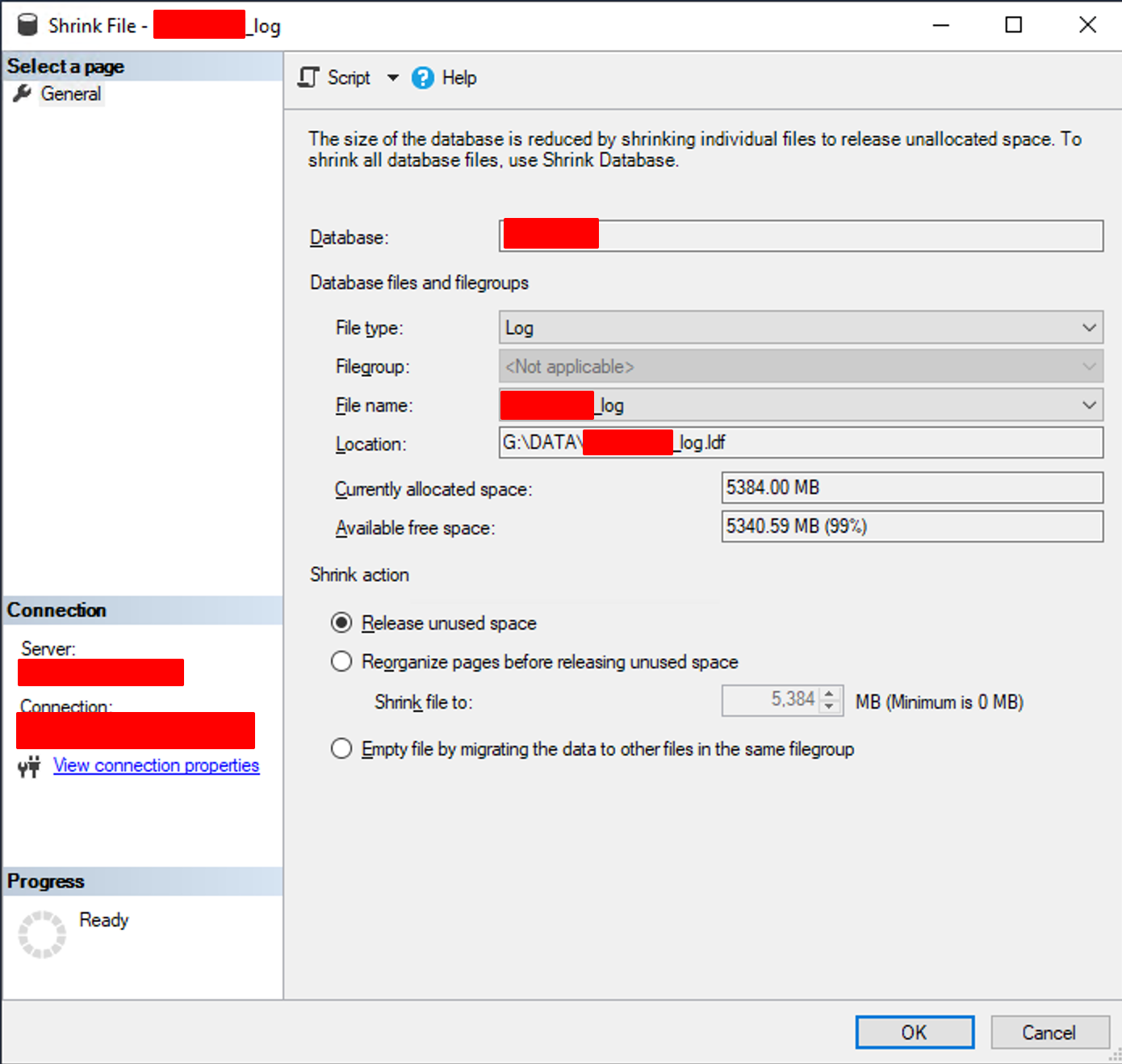
shrink arquivo de log
Prontinho! Fiz uma nova tentativa de restore e, dessa vez, foi sucesso total. 🙌
Resumo da Obra: Não foi possível evitar os múltiplos zeroing no disco de log — afinal, para arquivos de log, o Instant File Initialization (IFI) realmente não tem o mesmo efeito que nos arquivos de dados.
A solução? Realizei um shrink no arquivo de log, reduzindo significativamente o tamanho e a quantidade de VLFs que haviam sido criados durante o crescimento desordenado. Em seguida, gerei um novo backup e o restore fluiu sem travar nos 100%.

